
OpenShift Enterprise 3.11.69 on Intel NUC’s

Well, this is a very technical post and, in order to be useful for more people, I decided to write it in English.
Prerequisites
First of all, you should be able to have access to the OpenShift Enterprise repositories from Red Hat. Disclaimer: the current post is not related to CentOS based installations, also this post is not referring to OKD, MiniShift or even OpenShift on a single container (all-in-one), nope, this post is the technical review of OpenShift Enterprise 3.11 installed on a relatively small hardware.
Hardware
- Intel NUC Core i7 quad core, 32 GB of RAM, 256 GB PCIe Flash, 750 GB Hard Disk.
- Intel NUC Core i5 quad core, 16 GB of RAM, 256 GB PCIe Flash, 500 GB Hard Disk.
- Intel NUC Core i3 quad core, 16 GB of RAM, 128 GB PCIe Flash, 500 GB Hard Disk.
- HP MP 9, Intel Core i5 quad core, 16 GB of RAM, 256 SSD. This is the master node.
- Lenovo Laptop with RHEL 7.6 as bastion host.

Cluster components
- 1 Master node
- 3 Infra-compute nodes (infrastructure and computing nodes)
- 3 GlusterFS nodes
As you can advice, there are not enough nodes to cover the proposed architecture, so, I'm proposing to share the node resources in order to deploy the infra-compute nodes and the glusterfs nodes together. Of course, this kind of deployment is not recommended by Red Hat, remember, this is only a cluster for learning purposes, never for production purposes.
Brief list of OpenShift services to deploy
- Hawkular
- Cassandra
- Heapster
- Elasticsearch
- Fluentd
- Kibana
- Alert manager
- Prometheus
- Grafana
- GlusterFS
- Web Console
- Catalog
- Cluster console
- Docker registry
- OLM Operators
- Problem detector
- OC command line
- Heketi
- Master API
- Internal Router
- Scheduler
- and more...
Operating system
Red Hat Enterprise Linux (RHEL) 7.6 up to date with the following repositories enabled:
rhel-7-fast-datapath-rpms
rhel-7-server-extras-rpms
rhel-7-server-optional-rpms
rhel-7-server-ansible-2.6-rpms
rhel-7-server-ose-3.11-rpms
rhel-7-server-rpms
rh-gluster-3-client-for-rhel-7-server-rpms
rh-gluster-3-for-rhel-7-server-rpms
You can enable them by performing the following commands (on RHEL 7.6):
subscription-manager repos --enable=rhel-7-fast-datapath-rpms subscription-manager repos --enable=rhel-7-server-extras-rpms subscription-manager repos --enable=rhel-7-server-optional-rpms subscription-manager repos --enable=rhel-7-server-ansible-2.6-rpms subscription-manager repos --enable=rhel-7-server-ose-3.11-rpms subscription-manager repos --enable=rhel-7-server-rpms subscription-manager repos --enable=rh-gluster-3-client-for-rhel-7-server-rpms subscription-manager repos --enable=rh-gluster-3-for-rhel-7-server-rpms
RPM packages required
The required RPMs on every node and the bastion host should be: wget, git, net-tools, bind-utils, yum-utils, firewalld, java-1.8.0-openjdk, bridge-utils, bash-completion, kexec-tools, sos, psacct, openshift-ansible, glusterfs-fuse, docker and skopeo.
$ sudo yum -y install wget git net-tools bind-utils yum-utils firewalld java-1.8.0-openjdk \ bridge-utils bash-completion kexec-tools sos psacct openshift-ansible glusterfs-fuse docker skopeo
For the GlusterFS nodes (in this case, the nodei7, nodei5 and nodei3 nodes, also install Heketi Server on the master node) you should to install also the Heketi packages and the GlusterFS server packages:
$ sudo yum -y install heketi* gluster*
DNS (configuration required)
You need a fully qualified domain name service capable to handle wildcards, unfortunately dnsmasq is not enough for that purpose, you should to configure bind (named) or directly handling this by a DNS on your own domain (I did the last scenario). You can check this guide if you want to deploy Bind on your bastion host: https://access.redhat.com/documentation/en-us/openshift_enterprise/2/html/deployment_guide/sect-configuring_bind_and_dns
Adding these entries on the /etc/hosts file is not sufficient to deploy successfully the cluster due to OpenShift generates automatically internal rules on the Kubernetes pods and it takes them from the DNS configuration.
- master.calvarado04.com
- nodei7.calvarado04.com
- nodei5.calvarado04.com
- nodei3.calvarado04.com
- *.openshift.calvarado04.com <--- Wildcard, it must be making reference to the nodes where is deployed the router service (infra nodes).
- cluster-openshift.calvarado04.com <--- Master node public name
Don't forget to change the name of your nodes in the same way, you can perform that by:
$ sudo hostnamectl set-hostname nodei7.calvarado04.com $ hostname --fqdn nodei7.calvarado04.com
SSL Certificate (wildcard capable) for the OpenShift cluster
As you can see, If you want to install your own SSL certificate, that certificate must have wildcard capabilities, due to the basic SSL certificates won't work at all on OpenShift.
Your common name on your CSR request should be like this for the router certificate:
- *.calvarado04.com for the master
- *.openshift.calvarado04.com for the router subdomain (all the apps)
I added my certificate files on the bastion host on the directory /root/calvarado04.com, the files needed are:
- /root/calvarado04.com/calvarado04.pem (that is the certificate file merged with the intermediate certificate and the root certificate, the certificate content at the top of the file).
- /root/calvarado04.com/calvarado04.key with the private key generated when I generated the CSR file to obtain the SSL certificate.
- /root/calvarado04.com/calvarado04.ca with the root certificate.
- And the same for the router certificates (Openshift subdomain) on /root/calvarado04.com/openshift/
SELinux
Many people just disable SELinux on almost all new installation, this is not the case, SELinux is mandatory, it must be targered and enforcing on all nodes on the /etc/selinux/config file.
# This file controls the state of SELinux on the system. # SELINUX= can take one of these three values: # enforcing - SELinux security policy is enforced. # permissive - SELinux prints warnings instead of enforcing. # disabled - No SELinux policy is loaded. SELINUX=enforcing # SELINUXTYPE= can take one of these three values: # targeted - Targeted processes are protected, # minimum - Modification of targeted policy. Only selected processes are protected. # mls - Multi Level Security protection. SELINUXTYPE=targeted
Also please add the following rules to give permissions to the containers:
[root@bastion ~]# ansible nodes -a "setsebool -P virt_sandbox_use_fusefs on" [root@bastion ~]# ansible nodes -a "setsebool -P virt_use_fusefs on"
Firewalld
OpenShift used to work with IPtables, but this is not recommended anymore and any new deployment should be using firewalld instead. To mask and disable iptables:
$ sudo systemctl stop iptables $ sudo systemctl mask iptables $ sudo yum -y install firewalld $ sudo systemctl start firewalld.service $ sudo systemctl status firewalld.service $ sudo systemctl enable firewalld.service
Also add the GlusterFS Firewalld rules in order to allow the Gluster traffic on your nodes:
$ sudo firewall-cmd --zone=public --add-service=glusterfs $ sudo firewall-cmd --zone=public --add-service=glusterfs --permanent
NetworkManager
OpenShift uses the NetworkManager capabilities, so, is required to have enabled NetworkManager on the network device, for instance, check the following configuration:
USE_PEERDNS=yes and NM_CONTROLLED=yes
[root@nodei7 ~]# cat /etc/sysconfig/network-scripts/ifcfg-eno1 TYPE="Ethernet" PROXY_METHOD="none" BROWSER_ONLY="no" BOOTPROTO="dhcp" DEFROUTE="yes" IPV4_FAILURE_FATAL="no" IPV6INIT="yes" IPV6_AUTOCONF="yes" IPV6_DEFROUTE="yes" IPV6_FAILURE_FATAL="no" IPV6_ADDR_GEN_MODE="stable-privacy" NAME="eno1" UUID="e57de406-5cc2-415a-90c7-5671a76dd3a2" DEVICE="eno1" ONBOOT="yes" ZONE=public USE_PEERDNS=yes NM_CONTROLLED=yes
Restart the network and NetworkManager services:
$ sudo systemctl restart NetworkManager $ sudo systemctl restart network
SSH keys
Ansible requires SSH keys to run the required tasks on each node, let's create a key and distribute it to every nodes:
[root@bastion ~]# ssh-keygen
[root@bastion ~]# for host in master.calvarado04.com \
nodei7.calvarado04.com \
nodei5.calvarado04.com \
nodei3.calvarado04.com; \
do ssh-copy-id -i ~/.ssh/id_rsa.pub $host; \
done
Ansible
The official OpenShift Enterprise 3.11.69 installation method is by running the OpenShift playbooks provided by the RPMs. The Ansible version must be 2.6.x not 2.7 due to issues with some tasks.
GlusterFS
This deployment will be using GlusterFS on the most basic installation using only GlusterFS without blocks and is not including the GlusterFS Registry cluster on Convergent mode. However, this method is allowing you to use dynamic provisioning of the PVC's (Persistent Volume Claims), this feature is quite fancy because is not longer needed to declare manually the PV's once the cluster is up and running.
Heketi configuration on the master node
OpenShift uses Heketi to generate the Gluster topology from the master node to the Gluster nodes and it perform that task by using a SSH connection. That's why you need to configure Heketi on the master host by adding the user and ssh key on /etc/heketi/heketi.json.
Also change any timeout entry to a numeric value (on _sshexec_comment and _kubeexec_comment), like "gluster_cli_timeout": 900.
"_sshexec_comment": "SSH username and private key file information",
"sshexec": {
"keyfile": "/root/.ssh/id_rsa",
"user": "root",
"port": "22",
"fstab": "/etc/fstab",
"backup_lvm_metadata": false,
"gluster_cli_timeout": 900
},
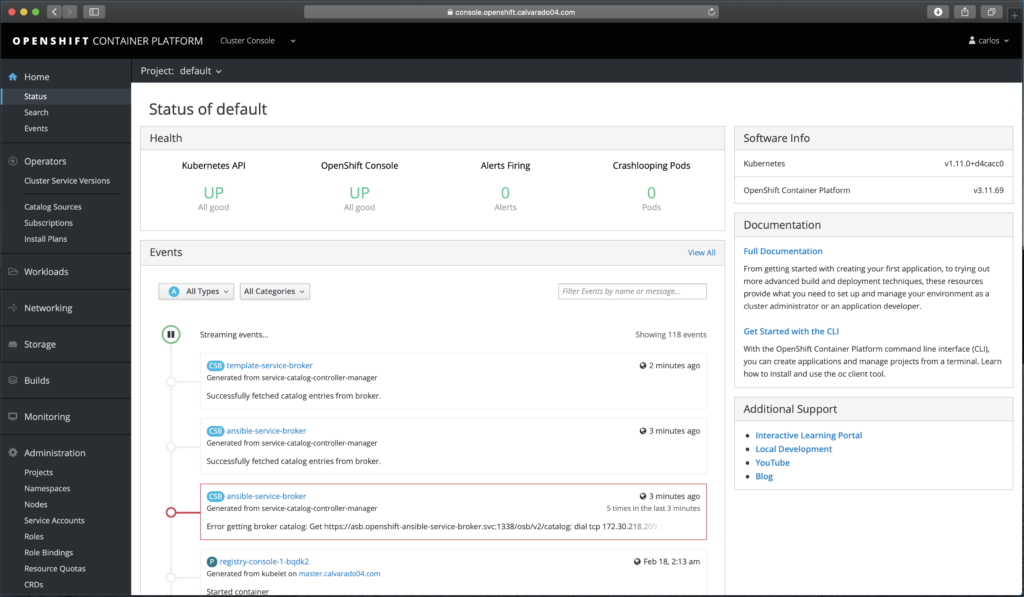
Wait for Gluster pods issue
On my first attempt to deploy the cluster I was stuck on a step that were wait for Gluster pods, the counter was timed out and the playbook was marked as failure. I checked the pods on the nodes and I saw them, I checked its logs and its logs was not showing any error. Researching more I found that could be a bug on the wait_for_pods.yml deployment playbook, located on /usr/share/ansible/openshift-ansible/roles/openshift_storage_glusterfs/tasks, concretely a cast issue due to the playbook is comparing a string with an integer.
This is the original playbook:
---
- name: Wait for GlusterFS pods
oc_obj:
namespace: "{{ glusterfs_namespace }}"
kind: pod
state: list
selector: "glusterfs={{ glusterfs_name }}-pod"
register: glusterfs_pods_wait
until:
- "glusterfs_pods_wait.results.results[0]['items'] | count > 0"
# There must be as many pods with 'Ready' staus True as there are nodes expecting those pods
- "glusterfs_pods_wait.results.results[0]['items'] | lib_utils_oo_collect(attribute='status.conditions') | lib_utils_oo_collect(attribute='status', filters={'type': 'Ready'}) | map('bool') | select | list | count == l_glusterfs_count | int"
delay: 30
retries: "{{ (glusterfs_timeout | int / 10) | int }}"
vars:
l_glusterfs_count: "{{ glusterfs_count | default(glusterfs_nodes | count ) }}"
And this is the fixed playbook:
---
- name: Wait for GlusterFS pods
oc_obj:
namespace: "{{ glusterfs_namespace }}"
kind: pod
state: list
selector: "glusterfs={{ glusterfs_name }}-pod"
register: glusterfs_pods_wait
until:
- "glusterfs_pods_wait.results.results[0]['items'] | count > 0"
# There must be as many pods with 'Ready' staus True as there are nodes expecting those pods
- "glusterfs_pods_wait.results.results[0]['items'] | lib_utils_oo_collect(attribute='status.conditions') | lib_utils_oo_collect(attribute='status', filters={'type': 'Ready'}) | map('bool') | select | list | count == l_glusterfs_count | int"
delay: 30
retries: "{{ (glusterfs_timeout | int / 10) | int }}"
vars:
l_glusterfs_count: "{{ glusterfs_count | default(glusterfs_nodes | count ) }} | int"
Wipe the GlusterFS disks
In order to install successfully the GlusterFS cluster, please wipe all the data from the chosen disks (in this case, the three GlusterFS nodes have the disk on /dev/sda, but that it could be different in your configuration, be careful), there must be on RAW format only. Warning: you can lose all your data if you are not careful. You can perform this by:
[root@bastion ~]# ansible glusterfs -a "wipefs -a -f /dev/sda"
HTPasswd (users and passwords for OpenShift)
This is a really simple configuration on this topic, I'm using only htpasswd, I saved my users on /root/htpasswd.openshift on the bastion host. You should to try with LDAP, it's more secure and advanced. Go ahead and learn something 😉
If you want to use the same way just:
[root@bastion ~]# htpasswd -c /root/htpasswd.openshift luke New password: Re-type new password: Adding password for user luke [root@broker ~]# cat /root/htpasswd.openshift luke:$apr1$SzuTxyhH$DlH976Tv2cDBccFZqJ3zf1
If you want to add more users, just omit the -c option:
[root@bastion ~]# htpasswd /root/htpasswd.openshift leia New password: Re-type new password: Adding password for user leia [root@bastion ~]# cat /root/htpasswd.openshift luke:$apr1$SzuTxyhH$DlH976Tv2cDBccFZqJ3zf1 leia:$apr1$UK2B49gy$qD/n3lKsoWXT0eRAMNoqm.
Run the installation playbooks
Once the package openshift-ansible is already installed on your bastion host and your SSH keys are already distributed on all your nodes, you can perform the installation of your OpenShift Cluster.
The happy path is quite simple:
- Fill your inventory file located in /etc/ansible/hosts
- Run the prerequisites playbook
- Run the deployment cluster playbook
- Check your installation
[root@bastion ~]# cd /usr/share/ansible/openshift-ansible/ [root@bastion openshift-ansible]# ansible-playbook playbooks/prerequisites.yml [root@bastion openshift-ansible]# pwd /usr/share/ansible/openshift-ansible [root@bastion openshift-ansible]# ansible-playbook playbooks/deploy_cluster.yml
The inventory file: /etc/ansible/hosts
The most important file is this one, every configuration will be taken from this file and every failure will be coming from here almost all the times.
This is my inventory file (without users and passwords):
[OSEv3:vars]
timeout=120
ansible_user=root
ansible_become=no
openshift_deployment_type=openshift-enterprise
openshift_disable_check="disk_availability,memory_availability,docker_image_availability,package_version"
openshift_image_tag=v3.11.69
openshift_pkg_version=-3.11.69
openshift_release=3.11.69
openshift_node_groups=[{'name': 'node-config-master', 'labels': ['node-role.kubernetes.io/master=true','runtime=docker']}, {'name': 'node-config-infra', 'labels': ['node-role.kubernetes.io/infra=true','runtime=docker']}, {'name': 'node-config-infra-compute','labels': ['node-role.kubernetes.io/infra=true','node-role.kubernetes.io/compute=true','runtime=docker']}, {'name': 'node-config-compute', 'labels': ['node-role.kubernetes.io/compute=true','runtime=docker'], 'edits': [{ 'key': 'kubeletArguments.pods-per-core','value': ['20']}]}]
logrotate_scripts=[{"name": "syslog", "path": "/var/log/cron\n/var/log/maillog\n/var/log/messages\n/var/log/secure\n/var/log/spooler\n", "options": ["daily", "rotate 7","size 500M", "compress", "sharedscripts", "missingok"], "scripts": {"postrotate": "/bin/kill -HUP cat /var/run/syslogd.pid 2> /dev/null 2> /dev/null || true"}}]
openshift_enable_olm=true
oreg_url=registry.redhat.io/openshift3/ose-${component}:${version}
oreg_auth_user=email@something.com
oreg_auth_password=passw0rd
# Set this line to enable NFS
#openshift_enable_unsupported_configurations=True
openshift_additional_registry_credentials=[{'host':'registry.connect.redhat.com','user':'email@something.com','password':'passw0rd','test_image':'mongodb/enterprise-operator:0.3.2'}]
openshift_examples_modify_imagestreams=true
os_firewall_use_firewalld=True
openshift_master_api_port=443
openshift_master_console_port=443
openshift_master_default_subdomain=openshift.calvarado04.com
openshift_master_cluster_public_hostname=cluster-openshift.calvarado04.com
openshift_master_cluster_hostname=master.calvarado04.com
osm_cluster_network_cidr=10.1.0.0/16
openshift_portal_net=172.30.0.0/16
hostSubnetLength=9
os_sdn_network_plugin_name='redhat/openshift-ovs-subnet'
openshift_use_openshift_sdn=true
openshift_master_identity_providers=[{'name': 'htpasswd_auth', 'login': 'true', 'challenge': 'true', 'kind': 'HTPasswdPasswordIdentityProvider'}]
openshift_master_htpasswd_file=/root/htpasswd.openshift
openshift_cluster_monitoring_operator_install=true
openshift_enable_service_catalog=true
template_service_broker_install=true
openshift_template_service_broker_namespaces=['openshift']
ansible_service_broker_install=true
ansible_service_broker_local_registry_whitelist=['.*-apb$']
openshift_master_dynamic_provisioning_enabled=true
openshift_master_overwrite_named_certificates=true
openshift_master_named_certificates=[{'certfile': '/root/calvarado04.com/calvarado04.pem', 'keyfile': '/root/calvarado04.com/calvarado04.key', 'names': ['cluster-openshift.calvarado04.com'], 'cafile': '/root/calvarado04.com/calvarado04.ca' }]
openshift_hosted_router_certificate={'cafile': '/root/calvarado04.com/openshift/calvarado04.ca', 'certfile': '/root/calvarado04.com/openshift/calvarado04.pem', 'keyfile': '/root/calvarado04.com/openshift/calvarado04.key'}
openshift_certificate_expiry_warning_days=20
openshift_hosted_router_replicas=3
openshift_hosted_registry_selector='node-role.kubernetes.io/infra=true'
openshift_hosted_registry_storage_volume_size=15Gi
openshift_hosted_registry_storage_kind=glusterfs
openshift_hosted_registry_replicas=3
openshift_hosted_registry_pullthrough=true
openshift_hosted_registry_acceptschema2=true
openshift_hosted_registry_enforcequota=true
openshift_hosted_registry_storage_volume_name=registry
openshift_metrics_install_metrics=true
openshift_metrics_storage_kind=dynamic
openshift_metrics_hawkular_nodeselector={"node-role.kubernetes.io/infra": "true"}
openshift_metrics_cassandra_nodeselector={"node-role.kubernetes.io/infra": "true"}
openshift_metrics_heapster_nodeselector={"node-role.kubernetes.io/infra": "true"}
openshift_metrics_storage_volume_size=15Gi
openshift_metrics_cassandra_pvc_storage_class_name="glusterfs-storage"
openshift_metrics_duration=1
openshift_prometheus_namespace=openshift-metrics
openshift_prometheus_node_selector={"node-role.kubernetes.io/infra":"true"}
openshift_prometheus_memory_requests=2Gi
openshift_prometheus_cpu_requests=750m
openshift_prometheus_memory_limit=2Gi
openshift_prometheus_cpu_limit=750m
openshift_prometheus_alertmanager_memory_requests=300Mi
openshift_prometheus_alertmanager_cpu_requests=200m
openshift_prometheus_alertmanager_memory_limit=300Mi
openshift_prometheus_alertmanager_cpu_limit=200m
openshift_prometheus_alertbuffer_memory_requests=300Mi
openshift_prometheus_alertbuffer_cpu_requests=200m
openshift_prometheus_alertbuffer_memory_limit=300Mi
openshift_prometheus_alertbuffer_cpu_limit=200m
openshift_logging_install_logging=true
openshift_logging_es_pvc_dynamic=true
openshift_logging_kibana_nodeselector={"node-role.kubernetes.io/infra": "true"}
openshift_logging_curator_nodeselector={"node-role.kubernetes.io/infra": "true"}
openshift_logging_es_nodeselector={"node-role.kubernetes.io/infra": "true"}
openshift_logging_es_pvc_size=15Gi
openshift_logging_es_pvc_storage_class_name="glusterfs-storage"
openshift_logging_es_memory_limit=3Gi
openshift_logging_es_cluster_size=1
openshift_logging_curator_default_days=1
openshift_storage_glusterfs_wipe=true
openshift_storage_glusterfs_heketi_wipe=true
openshift_storage_glusterfs_namespace=app-storage
openshift_storage_glusterfs_storageclass=true
openshift_storage_glusterfs_storageclass_default=true
openshift_storage_glusterfs_block_deploy=false
openshift_storage_glusterfs_heketi_image=registry.access.redhat.com/rhgs3/rhgs-volmanager-rhel7
openshift_storage_glusterfs_image=registry.access.redhat.com/rhgs3/rhgs-server-rhel7
openshift_storage_glusterfs_block_image=registry.access.redhat.com/rhgs3/rhgs-gluster-block-prov-rhel7
openshift_storage_glusterfs_s3_image=registry.access.redhat.com/rhgs3/rhgs-gluster-s3-server-rhel7
openshift_storage_glusterfs_timeout=900
osm_default_node_selector='node-role.kubernetes.io/compute=true'
[OSEv3:children]
masters
etcd
nodes
glusterfs
[masters]
master.calvarado04.com
[etcd]
master.calvarado04.com
[nodes]
master.calvarado04.com openshift_node_group_name='node-config-master' openshift_node_problem_detector_install=true openshift_schedulable=True
nodei7.calvarado04.com openshift_node_group_name='node-config-infra-compute' openshift_node_problem_detector_install=true openshift_schedulable=True
nodei5.calvarado04.com openshift_node_group_name='node-config-infra-compute' openshift_node_problem_detector_install=true openshift_schedulable=True
nodei3.calvarado04.com openshift_node_group_name='node-config-infra-compute' openshift_node_problem_detector_install=true openshift_schedulable=True
[glusterfs]
nodei7.calvarado04.com glusterfs_ip=192.168.0.73 glusterfs_devices='[ "/dev/sda" ]'
nodei5.calvarado04.com glusterfs_ip=192.168.0.72 glusterfs_devices='[ "/dev/sda" ]'
nodei3.calvarado04.com glusterfs_ip=192.168.0.70 glusterfs_devices='[ "/dev/sda" ]'
Redeploy script (it's only working on my cluster)
I wrote a script to redeploy my cluster, I'm sharing with you:
[root@bastion ~]# cat redeployOpenShift.sh #!/bin/bash cd /usr/share/ansible/openshift-ansible ansible-playbook playbooks/adhoc/uninstall.yml ansible-playbook -e "openshift_storage_glusterfs_wipe=true" playbooks/openshift-glusterfs/uninstall.yml ansible nodes -a "rm -rf /etc/origin" ansible nodes -a "rm -rf /var/lib/heketi /etc/glusterfs /var/lib/glusterd /var/log/glusterfs_devices /var/lib/gluster-block /var/log/gluster-block" ansible glusterfs -a "yum -y reinstall gluster*" ansible glusterfs -a "wipefs -a -f /dev/sda" ansible nodes -a "shutdown -r now" sleep 180 ansible glusterfs -a "systemctl restart glusterd" ansible glusterfs -a "systemctl stop glusterd" ansible nodes -a "setsebool -P virt_sandbox_use_fusefs on" ansible nodes -a "setsebool -P virt_use_fusefs on" ansible glusterfs -a "wipefs -a -f /dev/sda" ansible-playbook playbooks/deploy_cluster.yml [root@bastion ~]#
Final steps
Once the cluster will be up and running, just navigate to https://cluster-openshift.calvarado04.com the link it's only working for me 😉 and open the console.
To give cluster admin access to the desired user, enter to the master node and perform the following command:
[root@master ~]# oc whoami system:admin [root@master ~]# oc adm policy add-cluster-role-to-user cluster-admin admin [root@master ~]# oc adm policy add-cluster-role-to-user cluster-reader luke [root@master ~]# oc get pods -o wide [root@master ~]# oc get projects [root@master ~]# oc rollout latest project-developer [root@master ~]# oc logs
Gallery
References
- CHAPTER 4. DEPLOYING CONTAINERIZED STORAGE IN CONVERGED MODE https://access.redhat.com/documentation/en-us/red_hat_openshift_container_storage/3.11/html/deployment_guide/chap-documentation-deploy-cns
- Configuring OpenShift to use Custom Certificates http://v1.uncontained.io/playbooks/installation/custom_certificates.html
- Container-native storage 3.9: Enhanced day-2 management and unified installation within OpenShift Container Platform https://redhatstorage.redhat.com/2018/03/28/container-native-storage-3-9/
- Preparing your hosts https://docs.openshift.com/container-platform/3.11/install/host_preparation.html